Redisson布隆过滤器的原理、预热与误杀的妥协
前言
最近我在重构我的项目:CityVibe 智感生活与社交点评平台的底层逻辑,做高并发接口压测的时候,遇到了缓存穿透的问题。目前的系统是用 Redis 做分布式缓存来抗住高并发查询的。但是如果有人恶意大量请求一些数据库里没有的的商铺 ID,这些请求 Redis 里查不到,就会直接打到 MySQL ,大概率会马上被打到宕机。
一开始我用的也是传统的缓存空值策略来应对的,但是这种方案还是不够优雅。正好项目里已经集成了 Redisson,于是我花了一天时间,升级成了布隆过滤器。
这篇文章,就来复盘一下布隆过滤器的数学原理、在 SpringBoot 中的落地预热机制,以及在面对商铺下架删不掉的问题时,我如何妥协的。
为什么缓存空值不够优雅?
原本的缓存空值是这样的:如果用户查询 ID=9999 的商铺,数据库查不到,就在redis里存一个 key="shop:9999", value="", TTL=2分钟 的空字符串。下次再查这个 ID,Redis 就会直接拦截并返回空,就打不到数据库了。
但是如果每次请求都生成一个全新的、随机的 ID ,Redis 会把一大堆空值键值对存到内存里,这样非常浪费资源,还可能触发redis的内存淘汰策略,可能会挤走热点数据。
布隆过滤器的数学之美
布隆过滤器可以知道这个数据一定不存在,或者可能存在。
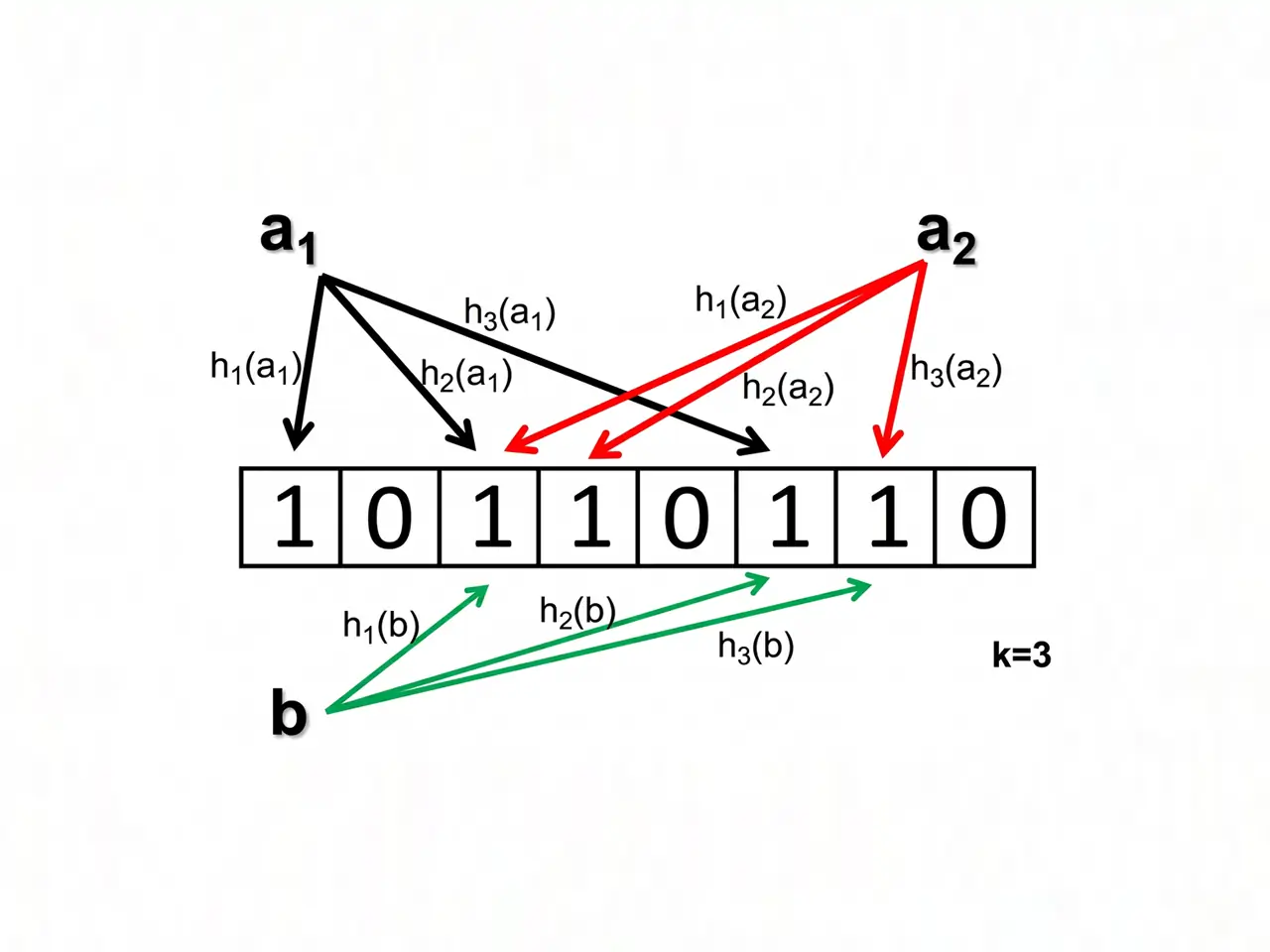
布隆过滤器的本质是一个很长的BitMap,初始状态下所有的位都是 0,其内部配备了多个不同的哈希函数。
写入:
假设我把存在的商铺 ID=1 放入布隆过滤器,它会经过比如 3 个哈希函数的计算,得出 3 个不同的索引值(比如 2、5、8),然后把位图上这 3 个位置的 0 改为 1。
查询:
当有人来查 ID=9999,同样用这 3 个哈希函数算一下,假设算出来的位置是 2、6、8。过滤器去位图上一看:第 2 和 8 位虽然是 1,但第 6 位是 0。
只要有一个位置是 0,这个 ID 就绝对没有被存进去过,然后就可以直接拦截返回了。
误判(可能): 有时候运气不好,算出来的位置正好被其他正常 ID 赋成了 1 ,过滤器会认为可能存在然后放行。不过如果控制位图的大小和哈希函数的个数,可以把误判率控制在1%以下。对于业务来说也很足够了。
SpringBoot 启动时的预热机制实战
布隆过滤器最大的特点是需要预热。在外部请求打进来之前,必须把数据库里现存的合法数据先塞进位图里。
利用 Redisson,代码其实非常简洁。我选择在 ShopServiceImpl 里利用 Spring 的 @PostConstruct 注解来实现容器启动时的自动预热:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Resource
private CacheClient cacheClient;
@Resource
private RedissonClient redissonClient;
@PostConstruct
public void initBloomFilter() {
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(SHOP_BLOOM_FILTER_KEY);
// 初始化布隆过滤器,预计存入10000个元素,容错率为0.01
bloomFilter.tryInit(10000L, 0.01);
// 查询全量商铺ID
List<Shop> list = this.lambdaQuery().select(Shop::getId).list();
if (list != null && !list.isEmpty()) {
for (Shop shop : list) {
bloomFilter.add(shop.getId());
}
}
}
// 查询接口
@Override
public Result queryById(Long id) {
// 先检查布隆过滤器
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(SHOP_BLOOM_FILTER_KEY);
if (!bloomFilter.contains(id)) {
return Result.fail("店铺不存在");
}
// 2. 放行到缓存/数据库逻辑...
// ...
}
}我还稍微改了一下新增商铺的接口,当有新商家入驻写入MySQL后,调一下
shopBloomFilter.add(newId)把它加进白名单,让数据的动态同步。@Override @Transactional(rollbackFor = Exception.class) public boolean save(Shop entity) { boolean saved = super.save(entity); if (saved && entity.getId() != null) { RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(SHOP_BLOOM_FILTER_KEY); bloomFilter.add(entity.getId()); } return saved; }
商铺下架了,删不掉怎么办?
文章写到这里,细心的朋友可能发现了:布隆过滤器不支持删除元素。
为什么?因为多个元素可能会共享位图上的同一个 1。如果把下架商铺对应的位改成 0,很可能会影响其他商铺,导致正常用户查不到数据。
那么问题来了,如果有个商家倒闭了,店铺被我从数据库和 Redis 物理删除了,但布隆过滤器里还留着它的印记,放行了对它的查询请求,怎么办?
一开始,作为有点完美主义的程序员,我想着能不能引入更高级的 布谷鸟过滤器 或者是 Counting Bloom Filter 来支持删除操作。但当我深入研究它们的底层实现后,我停手了。
考虑到这个 Trade-off ,我思考:
- 频率:一个平台每天可能几百上千万次查询,但商铺倒闭下架肯定是非常低频的。
- 代价:即便这个下架的 ID 被布隆过滤器放行了,它最多就是穿透到数据库执行一次主键查询。数据库查不到后,还是会走原先的逻辑,就是给 Redis 写入一个空值(TTL 2分钟)。
- 划算:为了这个极低频的场景,去引入复杂数倍的布谷鸟过滤器,不可避免的会增加资源开销和运维复杂度,在工程上讲是非常不划算的。
所以经过思考后,我最终觉得选择妥协挺好的。
结语
从一开始只会用 set null 堵漏,到利用数学的哈希位图进行降维打击,再到最后面对业务边界时的取舍妥协。这大概就是开发服务端应用最让人着迷的地方吧。